こんにちは.R&Dセンターに所属しているリサーチャーの山口です.今回は擬似的な異常音を作る方法を紹介します.
Contents
異音検知の問題点
異音検知の性能を評価するには正常音のデータと異常音のデータが必要です.
現実では異常音を手に入れることはなかなか難しいため,異常音になり得る異常音サンプルを使用してなるべく本物に近い異常音を作る必要があります.また,それらの異常音は様々なANRで作る必要があります.
ANRとは
ANR(Anomaly-to-Normal power Ratio)とは,異常音の信号の大きさが正常音の信号の大きさと比べてどのくらい大きいかを表す比率です.この定義は,信号が異常音,ノイズが正常音とした場合のSNR(Signal-to-Noise Ratio,SN比,信号雑音比)と同じです(文献[1]).
ANRの計算方法
ANRは以下の式で求めることができます.計算方法はSNRと同じため,この方法でSNRを求めることもできます.
$$ANR = 20 log_{10} \frac{S_{anomaly}}{S_{normal}}$$
\(S_{anomaly}\),\(S_{normal}\)は異常音と正常音のスペクトルの強さを表します.
今回は文献[1]の手法によりANRを計算していきます.文献[1]では次のようにANRを計算して疑似異常音を作成しています.
- 混ぜる異常音サンプルと正常音を同じ大きさにカットします.
- カットした正常音と異常音サンプルに対してフレーム単位のスペクトルパワーを計算します.フレームは窓幅512point,シフト幅256pointとしdbスケールで計算します.
音データを \(x\) とするとスペクトルは以下のように計算できます.
$$X_{\omega, \tau} = \| STFT(x) \|^2 $$
上式を使用してスペクトルパワーを計算します.
$$P_{\tau} = 20 log_{10}\sum_{\omega=1}^{\Omega}\left| X_{\omega, \tau} \right|$$ - 異常音サンプルと正常音の代表値として 2で計算した値のmedian値を計算します.
$$P_{median} = Median(P_{\tau})$$ - 作成したい疑似異常音が目標とするANRになるように3で取得した値を用いて正常音と異常音サンプルを混合する比率を調整します.
混合比率を \(\alpha \) とすると作成される疑似異常音は以下のように表すことができます.
$$x_{pseudo\_anomaly} =\alpha x_{anomaly} + x_{normal}$$
この式をSTFTし,スペクトルパワーを計算します.
$$S_{pseudo\_anomaly} =\alpha S_{anomaly} + S_{normal}$$
求めたいANRは \(S_{pseudo\_anomaly}\) と \(S_{normal}\)の比率であるため,これらをANRの定義式に代入します.
\[
\begin{align}
\ ANR &= 20 log_{10} \frac{S_{pseudo\_anomaly}}{S_{normal}} \\
&= 20 log_{10} (\alpha) + 20 log_{10} (S_{pseudo\_anomaly}) – 20 log_{10} (S_{normal})
\end{align}
\]
混合比率 \(\alpha\)について整理すると以下のようになります.
\[
\begin{align}
\ 20 log_{10}(\alpha) &= ANR – 20 log_{10} (S_{pseudo\_anomaly}) – 20 log_{10} (S_{normal}) \\
&= ANR – P_{pseudo\_anomaly} + P_{normal}\\
\alpha &= 10^{\frac{(ANR – P_{pseudo\_anomaly} + P_{normal})}{20}}
\end{align}
\] - 4で求めた比率を掛けた異常音サンプルと正常音を混合して疑似異常音を作成します.
任意のANRの疑似異常音を作ってみる
では,実際に疑似異常音を作成していきます.今回はモーターの内部に傷が入っておりキュイッキュイッといった音が発生しているといった状態を再現してみたいと思います・
データの準備
free soundからモータの音とキュイッキュイッの音を探しました.
使用した音源はSoXを使いsampling rateを44100Hzの16bitに変換し,必要な部分だけトリミングしています.
作成した疑似異常音
まずは,作成した疑似異常音を聞いてみましょう.ANRの数値が小さくなるほど異常の音が聞こえづらくなると思います.
Pythonで疑似異常音を作成
それでは,実際にpythonを使って疑似異常音を作成していきたいと思います.まずは必要なモジュールをimportします.
import numpy as np
import librosa初めに,音ファイルを読み込みます.音ファイルの読み込みはlibrosaを利用します.
anom_sample , sr = librosa.load('data/anomaly_sample/glass-creaking_trim.wav', sr=None)
norm , sr = librosa.load('data/nomal_sound/motor_1.wav', sr=None) 読み込んだ正常音と異常サンプルの音データの長さを揃え,無音区間を取り除きます.
今回は,異常サンプルが短いため,異常サンプルを繰り返すことで正常音と長さを揃えます.無音区間を取り除くのは,スペクトルパワーを計算するときに無音区間が多いと無音区間のスペクトルパワーの影響が出てしまうためです.
def align_audio_length(signal_1, signal_2):
while len(signal_2) < len(signal_1):
signal_2 = np.concatenate((signal_2,signal_2),axis=0)
signal_2 = signal_2[:len(signal_1)]
return signal_2
def cut_silence_section(signal, top_db=60):
index_array = librosa.effects.split(signal, ref=np.max, top_db=top_db)
signal_ = []
for index in index_array:
signal_.extend(signal[index[0]:index[1]])
signal_ = np.array(signal_)
return signal_
anom_sample = align_audio_length(norm, anom_sample)
anom_sample_cut = cut_silence_section(anom_sample, top_db=10)
norm_cut = cut_silence_section(norm, top_db=10)無音区間を取り除いた正常音と異常サンプルのフレーム単位スペクトルパワーを算出し,そのmedian値を算出します.
def calc_power(signal, win_length, hop_length):
S = librosa.stft(signal, n_fft=win_length, hop_length=hop_length
return np.median(20 * np.log10(np.sum(np.abs(S), axis=0)))
P_anom_sample = calc_power(anom_sample_cut, win_length=512, hop_length=256)
P_norm = calc_power(norm_cut, win_length=512, hop_length=256)
目標とするANRになるように異常サンプルを調整します.
def calc_scaler(P_norm, P_anom_sample, anr):
alpha = anr - (P_anom-P_norm)
alpha = 10**(alpha/20)
return alpha
scaler = calc_scaler(P_norm, P_anom_sample, anr=-15)
anom_sample_adjusted = scaler * anom_sample最後に,正常音と調整した異常サンプルを混合し疑似異常音を作成します.
anom = norm + anom_sample_adjustedまとめ
Pythonを用いて疑似異常音を作成しました.今回作成した疑似異常音は私がこんな音がなるだろうなという想像で作成しているため,実際に聞こえる異常音とはかけ離れているかもしれません.現場の方たちと共に疑似異常音を作成することでより現実に近い疑似異常音を作成することができると思います.
(補足)ANRやSNRでlogをとる理由について
音の大きさはヒトの聴覚が感じる音の強さです.これは感覚量と呼ばれる量になります.例えば,光や匂いなども感覚量となります.このような人間が感じる刺激と感覚を数式に表したのが,ウェーバー・フェヒナーの法則です.この法則はヒトの感覚の大きさは,受ける刺激の強さの対数に比例するというものです.式に表すと以下のようになります.
$$ P = k log \frac{I}{I_o} $$
\(P\): 感覚の強さ
\(I\), \(I_{o}\) :刺激の強さ
\(k\) : 定数
下図はウェーバー・フェヒナーの法則を図示化したものです.縦軸が感覚の強さ,横軸が刺激の強さです.例えば,刺激の強さが 2 から 3 へ変化したとき感覚の強さは約1.5倍ですが,200 から 300 へ変化したときの感覚の強さは約1倍で殆ど変わりません.
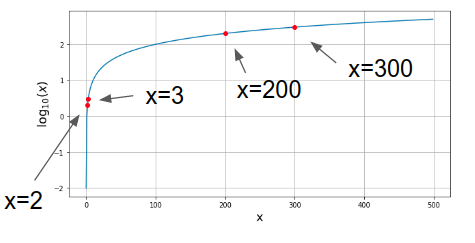
ANRやSNRもヒトの感覚量となります.計算するときは物理量であるスペクトルパワーから感覚量への変換が必要になるためlogを取る必要があります.