音データのData AugmentationライブラリAudiomentationsの紹介
今回の記事では、音データに対してData Augmentationを行うライブラリAudiomentationsを紹介します。
Contents
Audiomentationsについて
Audiomentationsは、画像系のData AugmentationライブラリAlbumentationsの影響を受けて作られた、音データに対するData Augmentationを行うライブラリです。
音データのData Augmentationライブラリには他にもtorchaudio等がありますが、Audiomentationsは変換の種類が豊富で、画像系のtorchvisionやAlbumentationsによく似たインターフェイスを持つ点が特徴です。
概要
この記事では主に以下の内容について説明します。
- Data Augmentationとは何か?
- Audiomentationsの使い方
- AudiomentationsとPyTorchを使って実際に学習を行ってみる
1. Data Augmentationとは何か?
Data Augmentationとは、手元にあるデータに対して加工を施してデータの量を増やす手法です。
Data Augmentationを行うことによって、以下のような効果が期待できます。
- データの量が少ない場合でも、実環境に近いデータを作り出してデータの量を増やし過学習を防ぐ
- trainデータとtestデータの分布が異なっている場合でも、trainデータを加工することでtestデータの分布に近づける
具体例1: 実環境に近いデータを作り出してデータ量を増やす
救急車のサイレンの音を検出するタスクを行いたいという状況を想定してみましょう。
録音できたtrainデータの件数が少なかったため、モデルの性能が目標値に少しだけ届きませんでしたが、もう少しデータを増やせば目標性能を達成できそうだということが判明しました。
そこで、Data Augmentationを試してみることにしました(もちろん追加で実データを録音できるのであればそれに越したことはありません)。
Data Augmentationには、データに小さなガウシアンノイズを加える、サイレンが鳴る区間をずらすといった手法を使うことにしました。サイレンの音に小さなノイズを加えたり音が鳴る区間をずらしたりしても、その音は実環境におけるサイレンの音と非常に近い音になると予想できるからです。
Data Augmentationの結果、性能は改善して無事に目標値を達成することができました。
これが、Data Augmentationによって実環境に近いデータの量を増やすケースの具体例です。
具体例2: trainデータとtestデータの分布を近付ける
今度は、機械の動作音から故障を検出するタスクを行いたいという状況を想定してみましょう。
trainデータは静かでほとんど雑音のない環境で録音しましたが、実際の現場で動作音を録音する際には、周囲の雑音が入ってきてしまうことが判明しました。
このままtrainデータで学習させたモデルを実際の現場で運用しようとすると、大幅に性能が悪化してしまうかもしれません。
そこで、trainデータを実際の現場での機械動作音に近づけるため、trainデータに対して雑音データを混ぜ合わせるData Augmentationを行いました。
その後、実際の現場から録音したtestデータを用いて、Data Augmentationを適用したモデルの性能を確認したところ、testデータにおいても正常にモデルが機能しており、無事に実環境においてもモデルを運用できそうだということが分かりました。
これが、Data Augmentationによってtrainデータとtestデータの分布を近付けるケースの具体例です。
2. Audiomentationsの使い方
Audiomentationsを実際にどのように使用するのか、コード例と一緒に見ていきましょう。
Audiomentationsはpipでインストールできます。
pip install audiomentationsAudiomentationsの使い方はとてもシンプルです。
まず、Composeと使いたいtransformをaudiomentationsからインポートします。
次に、Composeにtransformを渡して変換用のインスタンス(transforms)を作ります。
最後に、変換用のインスタンスに変換したい音データ(data)とそのサンプリングレート(sr)を渡すと、変換後のデータ(augmented_data)が返ってきます。
from audiomentations import Compose, AddGaussianNoise, Shift # version: '0.12.1'
import librosa # version: '0.8.0'
import os
import random
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context("talk")
# SEED値の固定
# これがないと実行する度に結果が変わってしまう
def seed_set(seed=42):
random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
np.random.seed(seed)
seed_set()
# Data Augmentationの定義
transforms = Compose( [
# 確率pでmin_amplitudeとmax_amplitudeの範囲からランダム(一様分布)に選んだ値を標準偏差に持つガウシアンノイズを付加する
AddGaussianNoise(min_amplitude=0.02, max_amplitude=0.02, p=1.0),
# 確率pでmin_fractionとmax_fractionの範囲からランダムに選んだ割合の時間で音の波形をずらす
Shift(min_fraction=-0.5, max_fraction=0.5, p=1.0),
])
# サンプル音源のロード
data, sr = librosa.load(librosa.example("nutcracker"))
# サンプル音源にData Augmentationを適用
augmented_data = transforms(samples=data, sample_rate=sr)
# 波形の描画
plt.figure(figsize=(20, 5))
_x = np.arange(0, len(data)) / sr
plt.plot(_x, data)
plt.xlabel("time(sec)")
plt.title("Raw Wave")
plt.show()
plt.figure(figsize=(20, 5))
_x = np.arange(0, len(augmented_data)) / sr
plt.plot(_x, augmented_data)
plt.xlabel("time(sec)")
plt.title("Augmented Wave")
plt.show()
結果
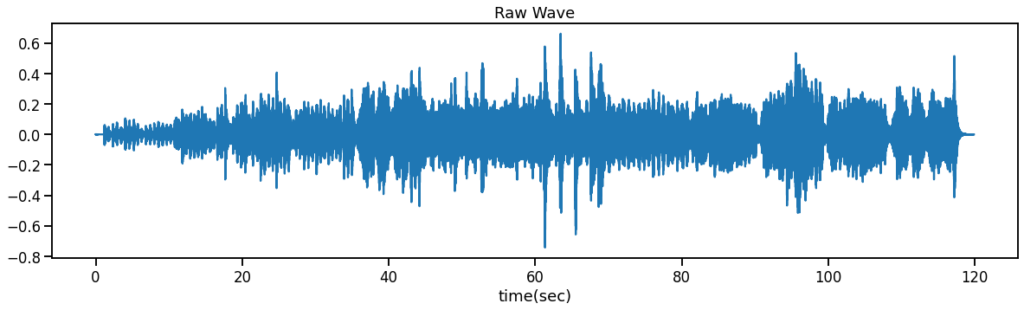
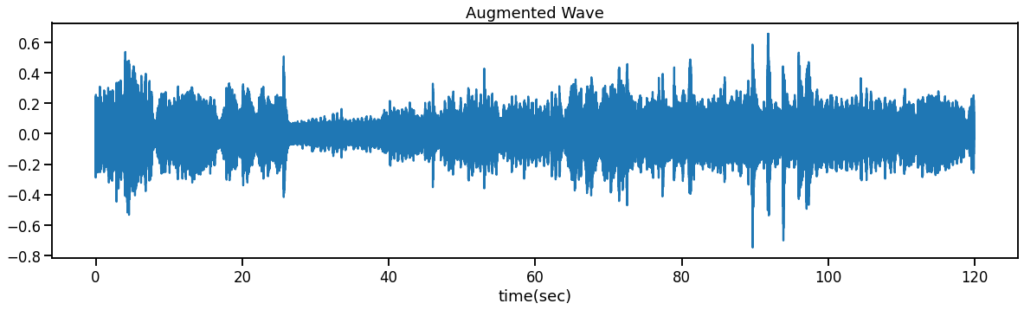
上が元々の波形で、下がData Augmentationによって加工された波形になっています。
見比べると、下の波形にはガウシアンノイズが付加され、25秒程後ろにシフトされている様子が分かります。
3. AudiomentationsとPyTorchを使って実際に学習を行ってみる
それでは、実際にAudiomentationsを使って学習を行ってみましょう。
学習データには環境音のデータセットESC-50のサブセットであるESC-10を使用し、モデルにはLeeNet24を使用します。
この使用例におけるOSや主なライブラリ等のバージョンは以下の通りです。
- OS: Ubuntu18.04
- Python: 3.7.6
- audiomentations: 0.12.1
- torch: 1.6.0+cu101
- catalyst: 20.06
- librosa: 0.8.0
ライブラリのimport
import datetime
import glob
import os
import random
import numpy as np
import pandas as pd
import librosa
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import catalyst
from catalyst import dl
from catalyst.core.callbacks.scheduler import SchedulerCallback
from catalyst.utils import metrics
from sklearn.metrics import accuracy_score
from audiomentations import Compose, Gain, TimeStretchDatasetとDataloaderの作成
ESC-10のDatasetとDataloaderを作成します。
Datasetの作成
Tokozume and Harada (ICASSP 2017) と同様に、trainデータについては5秒間のデータから1.5秒の区間をランダムに抜き出し、ラベルはそのままにします。validデータとtestデータについては、5秒間のデータから1.5秒幅で0.2秒ずつずらした区間を抜き出して、すべての区間に対する予測の平均を全体に対する予測とします。
df = pd.read_csv("../data/ESC-50-master/meta/esc50.csv")
df = df[["filename", "fold", "target", "esc10"]]
df = df[df["esc10"] == True].reset_index(drop=True)
label_dict = {
0: 0,
1: 1,
10: 2,
11: 3,
12: 4,
20: 5,
21: 6,
38: 7,
40: 8,
41: 9,
}
class ESC10Dataset(torch.utils.data.Dataset):
def __init__(self, root, df, label_dict, phase="train", transform=None, sr=44100, length=66150):
self.root = root
self.df = df
self.phase = phase
self.transform = transform
self.sr = sr
self.length = length
self.label_dict = label_dict
if self.phase == "train":
self.data = self.df[df["fold"].isin([1, 2, 3])].reset_index(drop=True)
elif self.phase == "valid":
self.data = self.df[df["fold"].isin([4])].reset_index(drop=True)
elif self.phase == "test":
self.data = self.df[df["fold"].isin([5])].reset_index(drop=True)
self.num_data = len(self.data)
def __len__(self):
return self.num_data
def __getitem__(self, idx):
filename = self.data.loc[idx, "filename"]
data, _ = librosa.load(os.path.join(self.root, filename), sr=self.sr)
label = self.data.loc[idx, "target"]
label = self.label_dict[label]
label = torch.Tensor([label]).long().squeeze(0)
if self.phase == "train":
crop_index = np.random.randint(0, 5 * self.sr - self.length + 1)
data = data[crop_index:crop_index + self.length]
if self.transform:
data = self.transform(data, sample_rate=self.sr)
data = torch.from_numpy(data).unsqueeze(0).unsqueeze(0)
if self.phase != "train":
data = np.array([data[i:i + self.length] for i in range(0, 5 * self.sr - self.length + 1, int(0.2 * self.sr))])
data = torch.from_numpy(data).unsqueeze(1).unsqueeze(1)
return {"data": data, "label": label}Dataloaderの作成
Tokozume, Ushiku and Harada (ICLR 2018) でStrong Data Augmentationと呼ばれている手法を参考に、GainとTimeStretchを今回のData Augmentationの手法として使用しました。
path_root = "../data/ESC-50-master/audio" # ESC-50の音データが存在するディレクトリのパス
batch_size = 64
num_workers = 4
transforms = Compose([
# 確率pでmin_gain_in_db, max_gain_in_dbの範囲からランダム(一様分布に従う)に選んだ値のdB分だけ音を増幅/減衰させる
# 例えば、min_gain_in_db=6, max_gain_in_db=6, p=0.5ならば、確率0.5で6dB分だけ音を増幅させる
Gain(min_gain_in_db=-6, max_gain_in_db=6, p=1.0),
# 確率pでmin_rate, max_rate, の範囲からランダム(一様分布に従う)に選んだ値の倍率だけ音を伸縮させる
# leave_length_unchangedがTrueの場合、伸縮させる前と後のデータの長さが同じになるように0埋めや後半部分の切り取りを行う
TimeStretch(min_rate=0.8, max_rate=1.25, leave_length_unchanged=True, p=1.0),
])
def collate_fn(batch):
data, label = batch[0]["data"], batch[0]["label"]
return {"data": data, "label": label.unsqueeze(0)}
loaders = {
"train": torch.utils.data.DataLoader(
ESC10Dataset(root=path_root, df=df, label_dict=label_dict, phase="train", transform=transforms),
shuffle=True,
batch_size=batch_size,
pin_memory=True,
num_workers=num_workers,),
"valid": torch.utils.data.DataLoader(
ESC10Dataset(root=path_root, df=df, label_dict=label_dict, phase="valid"),
shuffle=False,
batch_size=1,
pin_memory=True,
num_workers=1,
collate_fn=collate_fn,
),
}モデルの定義
モデルにはLeeNet24を使用します。音データをニューラルネットで扱う際には、データをメルスペクトログラムに変換してから画像のように学習を行う手法も一般的ですが、今回は音の波形データをそのまま入力できるLeeNetを使うことにしました。
モデルの実装にあたって、以下のリポジトリを参考にしました。
https://github.com/qiuqiangkong/audioset_tagging_cnn
def init_layer(layer):
"""Initialize a Linear or Convolutional layer. """
nn.init.xavier_uniform_(layer.weight)
if hasattr(layer, 'bias'):
if layer.bias is not None:
layer.bias.data.fill_(0.)
def init_bn(bn):
"""Initialize a Batchnorm layer. """
bn.bias.data.fill_(0.)
bn.weight.data.fill_(1.)
class LeeNetConvBlock2(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride):
super(LeeNetConvBlock2, self).__init__()
self.conv1 = nn.Conv1d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size, stride=stride,
padding=kernel_size // 2, bias=False)
self.conv2 = nn.Conv1d(in_channels=out_channels,
out_channels=out_channels,
kernel_size=kernel_size, stride=1,
padding=kernel_size // 2, bias=False)
self.bn1 = nn.BatchNorm1d(out_channels)
self.bn2 = nn.BatchNorm1d(out_channels)
self.init_weight()
def init_weight(self):
init_layer(self.conv1)
init_layer(self.conv2)
init_bn(self.bn1)
init_bn(self.bn2)
def forward(self, x, pool_size=1):
x = F.relu_(self.bn1(self.conv1(x)))
x = F.relu_(self.bn2(self.conv2(x)))
if pool_size != 1:
x = F.max_pool1d(x, kernel_size=pool_size, padding=pool_size // 2)
return x
class LeeNet24(nn.Module):
def __init__(self, classes_num):
super(LeeNet24, self).__init__()
window = 'hann'
center = True
pad_mode = 'reflect'
ref = 1.0
amin = 1e-10
top_db = None
self.conv_block1 = LeeNetConvBlock2(1, 64, 3, 3)
self.conv_block2 = LeeNetConvBlock2(64, 96, 3, 1)
self.conv_block3 = LeeNetConvBlock2(96, 128, 3, 1)
self.conv_block4 = LeeNetConvBlock2(128, 128, 3, 1)
self.conv_block5 = LeeNetConvBlock2(128, 256, 3, 1)
self.conv_block6 = LeeNetConvBlock2(256, 256, 3, 1)
self.conv_block7 = LeeNetConvBlock2(256, 512, 3, 1)
self.conv_block8 = LeeNetConvBlock2(512, 512, 3, 1)
self.conv_block9 = LeeNetConvBlock2(512, 1024, 3, 1)
self.fc1 = nn.Linear(1024, 1024, bias=True)
self.fc_audioset = nn.Linear(1024, classes_num, bias=True)
self.init_weight()
def init_weight(self):
init_layer(self.fc1)
init_layer(self.fc_audioset)
def forward(self, input, mixup_lambda=None):
x = input.squeeze(1)
# Mixup on spectrogram
if self.training and mixup_lambda is not None:
x = do_mixup(x, mixup_lambda)
x = self.conv_block1(x)
x = F.dropout(x, p=0.1, training=self.training)
x = self.conv_block2(x, pool_size=3)
x = F.dropout(x, p=0.1, training=self.training)
x = self.conv_block3(x, pool_size=3)
x = F.dropout(x, p=0.1, training=self.training)
x = self.conv_block4(x, pool_size=3)
x = F.dropout(x, p=0.1, training=self.training)
x = self.conv_block5(x, pool_size=3)
x = F.dropout(x, p=0.1, training=self.training)
x = self.conv_block6(x, pool_size=3)
x = F.dropout(x, p=0.1, training=self.training)
x = self.conv_block7(x, pool_size=3)
x = F.dropout(x, p=0.1, training=self.training)
x = self.conv_block8(x, pool_size=3)
x = F.dropout(x, p=0.1, training=self.training)
x = self.conv_block9(x, pool_size=1)
(x1, _) = torch.max(x, dim=2)
x2 = torch.mean(x, dim=2)
x = x1 + x2
x = F.dropout(x, p=0.5, training=self.training)
x = F.relu_(self.fc1(x))
clipwise_output = self.fc_audioset(x)
return clipwise_outputモデルの学習
モデルの学習には、CatalystというPyTorchをKerasのように簡単に書けるようにしてくれるフレームワークを使います。
class CustomRunner(dl.Runner):
def predict_batch(self, batch):
# model inference step
return torch.mean(self.model(batch["data"]), dim=0).unsqueeze(0)
def _handle_batch(self, batch):
# model train step
data = batch["data"]
label = batch["label"]
if self.is_train_loader:
predict = self.model(data)
loss = F.cross_entropy(predict, label)
accuracy, _ = metrics.accuracy(predict, label, topk=(1, 3))
self.batch_metrics = {"loss": loss, "accuracy": accuracy}
loss.backward()
self.optimizer.step()
self.optimizer.zero_grad()
if self.is_valid_loader:
# model valid step
predict = self.model(data)
predict = torch.mean(predict, dim=0).unsqueeze(0)
loss = F.cross_entropy(predict, label)
accuracy, _ = metrics.accuracy(predict, label, topk=(1, 3))
self.batch_metrics = {"loss": loss, "accuracy": accuracy}
device = catalyst.utils.get_device()
runner = CustomRunner(device=device)
model = LeeNet24(10)
model.init_weight()
optimizer = torch.optim.SGD(
model.parameters(),
lr=0.01,
momentum=0.9,
weight_decay=5e-4,
nesterov=True
)
scheduler = optim.lr_scheduler.MultiStepLR(
optimizer,
milestones=[300,450],
gamma=0.1
)
# logging用のディレクトリ名を生成する
def attach_current_time(file_name: str):
'''returns file_name attached with time information with format:%Y_%m_%d_%H_%M_%S
Args:
file_name(str): file_name to attach time information
Returns:
str: file_name attached with time information
Examples:
file_name = 'example.txt'
file_name = attach_now(file_name)
print(file_name) # example_2020_11_24_09_08_12.txt
'''
file_name_without_extension, extension = os.path.splitext(file_name)
now = datetime.datetime.now()
return file_name_without_extension + '_{0:%Y_%m_%d_%H_%M_%S}'.format(now) + extension
model_name = "LeeNet24_audiomentations"
logdir = attach_current_time("../logs/log_" + model_name)runner.train(
model=model,
optimizer=optimizer,
scheduler=scheduler,
loaders=loaders,
logdir=logdir,
num_epochs=600,
verbose=True,
load_best_on_end=True,
callbacks=[
SchedulerCallback(mode="epoch"),
]
)testデータの評価
test_loader = torch.utils.data.DataLoader(
ESC10Dataset(root=path_root, df=df, label_dict=label_dict, phase="test"),
shuffle=False,
batch_size=1,
pin_memory=True,
num_workers=1,
collate_fn=collate_fn,)
model.eval()
outputs = torch.Tensor()
outputs = outputs.to(device)
labels = torch.Tensor()
labels = labels.to(device)
with torch.no_grad():
for batch in test_loader:
data = batch["data"].to(device)
label = batch["label"].to(device)
output = model(data)
output = torch.argmax(torch.mean(output, dim=0)).unsqueeze(0)
outputs = torch.cat((outputs, output))
labels = torch.cat((labels, label))
accuracy_test = accuracy_score(
labels.to('cpu').detach().numpy().copy(),
outputs.to('cpu').detach().numpy().copy(),)
print(accuracy_test)- Data Augmentationあり: Accuracy=0.7875, Cross Entropy Loss=0.3745
- Data Augmentationなし: Accuracy=0.7375, Cross Entropy Loss=0.6000
テストの結果、Data Augmentationによってモデルの性能を改善できることが分かりました。
Validation Curveの確認
Validation LossとValidation Accuracyの推移も確認してみましょう。
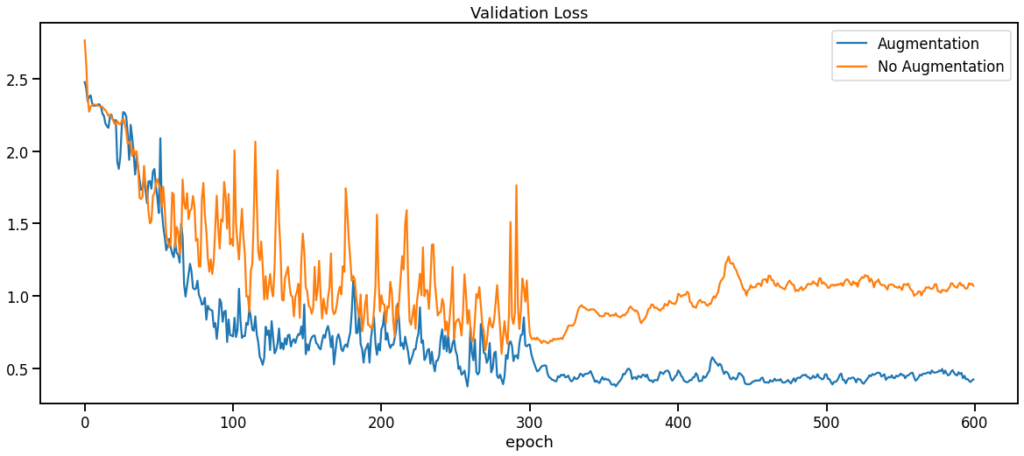
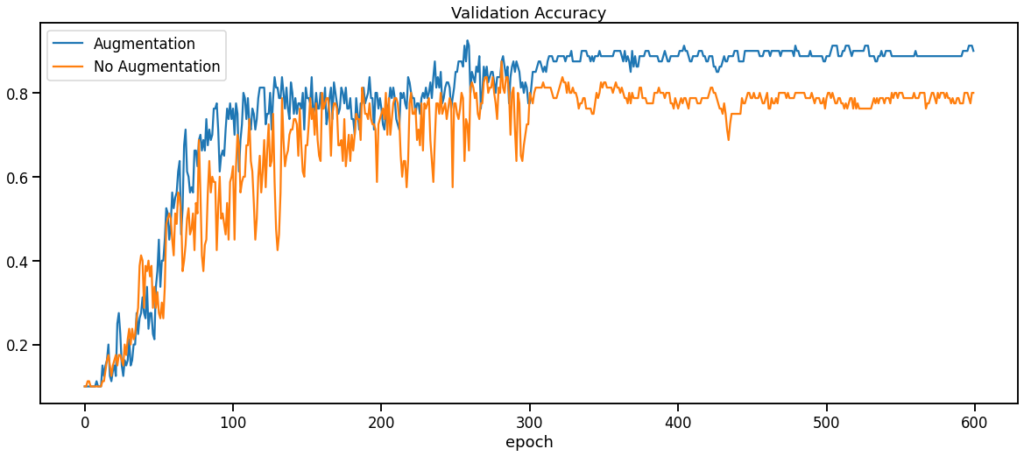
Data Augmentationを適用した場合の方が、適用しなかった場合に比べてLossやAccuracyが早く収束し、より良い値を達成しています。
また、Data Augmentationを適用しない場合はepochが300を少し越えた辺りからLossが徐々に増加しているのに対して、適用した場合は最後のepochまでLossの挙動が落ち着いています。
まとめ
以上の結果から、Data Augmentationにはモデルの性能を改善する効果と過学習を防ぐ効果を期待できることが分かりました。
今回の記事では、音データのData AugmentationライブラリAudiomentationsの使い方を説明し、Data Augmentationの有効性について実験を行い確認しました。
この記事を通して、音データ分析の魅力を少しでもお伝えできたのであれば幸いです。
References
- Learning Environmental Sounds with End-to-end Convolutional Neural Network (Yuji Tokozume and Tatsuya Harada, ICASSP, 2017).
- Sample-level Deep Convolutional Neural Networks for Music Auto-tagging Using Raw Waveforms (Jongpil Lee, Jiyoung Park, Keunhyoung Luke Kim and Juhan Nam, Sound, Music Computing Conference, 2017)
- Learning from Between-class Examples for Deep Sound Recognition (Yuji Tokozume, Yoshitaka Ushiku, and Tatsuya Harada, ICLR 2018).
- PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition (Qiuqiang Kong, Yin Cao, Turab Iqbal, Yuxuan Wang, Wenwu Wang and Mark D. Plumbley, IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020)
最近の投稿
- Hmcomm、AIによる水道管漏水検知の実証が完了― 守山市で成果報告会を開催、熟練調査員と同程度の判定結果を確認 ― 2026年03月18日
- 守山市での漏水検知実証実験に関する取り組みが水道産業新聞に掲載 2026年03月11日
- Hmcomm、山形県企業局と連携し、設備の故障予兆検知の実現に関する取り組みを開始 2026年02月16日
- Hmcomm、内閣官房主催『イチBizアワード』にてESRIジャパン協賛企業賞を受賞― 音×衛星データ×AIによる漏水検知の実装力と社会的価値を評価 ― 2026年02月13日
- 国土交通省「インフラ施設管理AI協議会」 有識者委員として参画― インフラ維持管理DXに関する当社の知見が評価され選定 ― 2025年12月12日
- 守山市における「水道管漏水検知システム」実証が最終フェーズへ― 守山市公式noteにて取り組み進展が紹介されました ― 2025年12月08日
- Hmcomm、SecondSightと連携し、異常音検知AIアプリ「FAST-D」によるLNG気化プラントの設備監視を開始〜夜間巡回業務の一部代替から開始し、保全業務の効率化を推進〜 2025年10月29日
- 守山市での漏水検知実証実験に関する取り組みが水道産業新聞に掲載されました 2025年08月08日
- 「衛星データ×FAST-D 漏水検知システム」が守山市官民連携プロジェクトに採択—Hmcomm、広域から精密まで一気通貫で漏水を検知する実証実験を開始— 2025年07月17日
- 山形県企業局様との送水ポンプ異常検知に関する取り組みについての取材記事が水道産業新聞に掲載されました 2025年07月14日
カテゴリー
アーカイブ
- 2026年3月
- 2026年2月
- 2025年12月
- 2025年10月
- 2025年8月
- 2025年7月
- 2025年6月
- 2022年8月
- 2022年7月
- 2022年6月
- 2022年5月
- 2022年4月
- 2022年3月
- 2022年2月
- 2022年1月
- 2021年12月
- 2021年11月
- 2021年10月
- 2021年9月
- 2021年8月
- 2021年7月
- 2021年6月
- 2021年5月
- 2021年4月
- 2021年3月
- 2021年2月
- 2021年1月
- 2020年10月
- 2020年9月
- 2020年8月
- 2020年6月
- 2020年5月
- 2020年2月
- 2019年10月
- 2019年9月
- 2019年4月
- 2018年12月
- 2018年9月
- 2018年6月