Audio Spectrogram Transformerの解説と実験
こんにちは,リサーチャーの二階堂です.
NLP界隈では必須級の扱いとなっているTransformerベースのモデルですが,昨今画像処理や物体検出分野における活躍も目を見張るものがあります.
そんな中,音データにおけるクラス分類タスクにおいても,純粋なAttentionベースのモデルであるAudio Spectrogram Transformer (AST)の論文が数ヶ月前に発表されましたので,今回はその紹介と簡単な実験を行いたいと思います.
Contents
論文の紹介
ASTの論文の主な要点は次の2つだと感じました.
- Vision Transformer(ViT)をベースに,メルスペクトログラムを入力にできるAttentionベースのモデルを発表
- ImageNetを学習させたViTからの転移学習により,精度向上を確認.
モデル構成
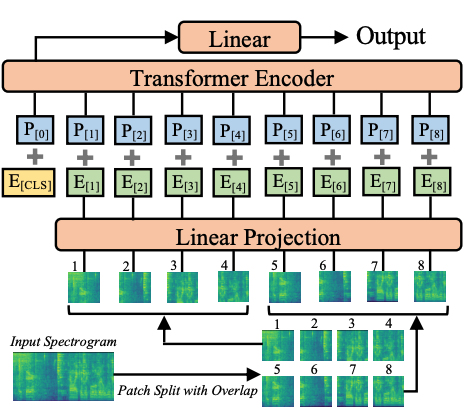
ASTの仕組みですが,Vision Transformer(ViT)とかなり似ています.ViTでは,画像をTransformerのEncoderに食わせるための工夫として,画像をパッチに分割した上で埋め込むPatch Embeddingという仕組みを用いています.ASTにおいてもその仕組みは用いられていて,メルスペクトログラムをパッチに分割し,線形投影層(上記画像のLinear Projection)を用いて埋め込み空間が生成されます.Vitと異なるのは入力で,ViTでは3ch(RGB)の画像を入力としますが,ASTでは1chのメルスペクトログラムを入力とします.Encoder部,MLP部はViTと同じような構造になっています.
さて,前述した通りViTとASTの構造はかなり似ています.Transformerの欠点は,Transformerが学習に大量のデータを必要とすることです.しかし,一般的な音声のデータセットにおいて,そこまで巨大なデータセットはありません.そこで,以下の方法でASTではImageNetで事前学習されたViTのパラメータをASTの初期パラメータとして使用する方法を提案しています.
1. CLSトークン*をカット
2. 事前学習された位置埋め込み層の重みをメルスペクトログラムの位置埋め込みに適用できるよう補間
例えば、16×16サイズのパッチを作る場合、384×384の画像ではpatch embeddingの数は576個となります.一方で例えば10秒の音声を入力とするメルスペクトログラムではpatch embeddingの数は12*100個となります。そのため、補間により576個のpatch embeddingの重みを適用できるようにします.論文中では,バイリニア補間法を用いています.
3. CLSトークンをそのまま流用し,先頭に結合
以上の流れにより,ViTにおけるImageNetの空間情報をASTに流用しています.この手法が有用かどうかは,次の実験で確かめられています.
*CLSトークン…BERTにおいて,文章の先頭につけられる特殊トークン.ViTにおいてもこの仕組みは用いられていて,画像を線形投影層に通した後,先頭にこの特殊トークンがつけられる.
論文における実験
AudioSetにおける評価
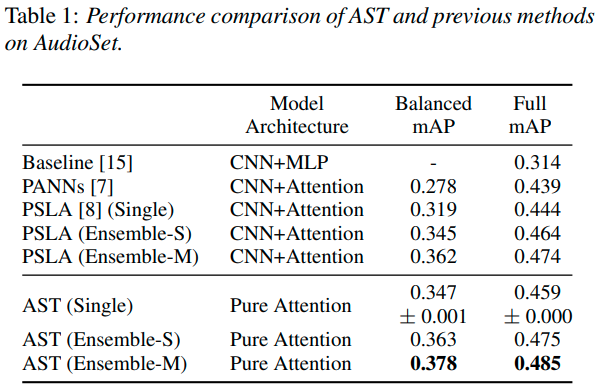
AudioSetでは,既存の高性能モデルとの比較を行っています.実験によると,シングルモデル,アンサンブルモデル両方共SOTAを達成しています.ASTと,比較に用いたモデル全てImageNetの事前学習を利用しているようです.
また,Full mAPは全てのAudioSetのデータ,balanced mAPは全体の1%を用いたデータにおける評価なのですが,1%の少ないデータでも高い精度だったとのことです.さらに学習速度も速いようで,PSLAでは30epochを要したが,ASTは5epochで高い精度が出るとのことでした.
さらに,AudioSetを用いて以下の検証もしています.
ImageNetの事前学習の影響
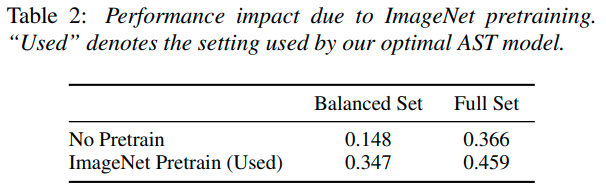
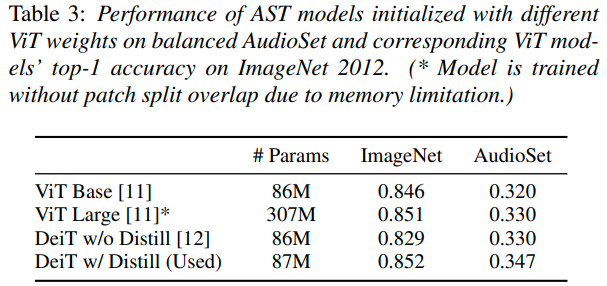
まず,ImageNetの事前学習の有無による精度への影響ですが,こちらはやはりImageNetの事前学習があったほうがかなり高い精度が出ていそうです.また,事前学習はDeiTが一番良かったとのことで,これはImageNetの評価結果と相関する形となりました.
位置埋め込み再利用の影響

次に位置埋め込みの再利用ですが,表を見ると,位置埋め込み部分を再初期化しても,事前学習の効果は失われないことがわかります.ただし,提案した位置埋め込みの補間を使ったほうが,事前学習時の空間情報を適用できるため,精度は顕著に向上するようです,補間方法の違いでは,あまり差が出ないことも確認されました.(最近傍法の方が計算コストは低いはずです.)
パッチ分割のオーバーラップの影響
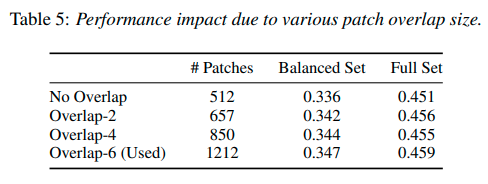
メルスペクトログラムのパッチ分割に関しては,オーバーラップが大きい方が精度が向上するようですが,その分計算量も大きくなってしまいます.しかし,オーバーラップがない場合でもSOTAを達成しているようです.
パッチの形状とサイズの影響
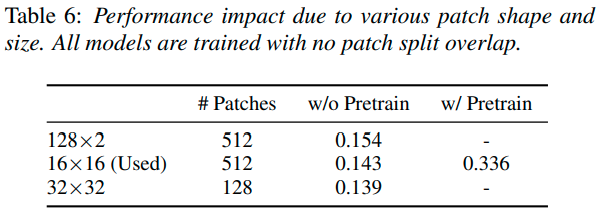
これは結構興味深い結果が出ていて,入力がメルスペクトログラムということもあり,画像を縦に分割したほうが精度が高いようです.しかし,ImageNetと同じパッチ分割方式は16×16のため,結果的にそちらのほうが精度が高くなっています.ですが,縦に分割したほうがメルスペクトログラムの時系列を崩さずに入力できているため,こちらの分割方式で無理やりImageNetの事前学習を用いた時どの程度の精度が出るのかは非常に気になるところです.
他のデータセットでの実験
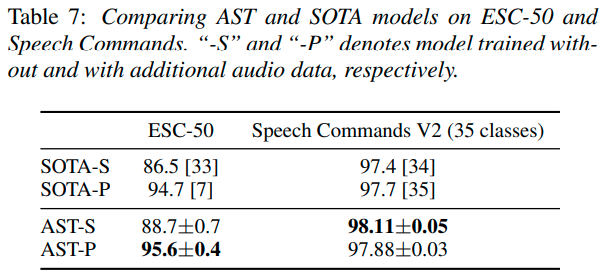
Speech Commands V2という,35種類の一般的な音声コマンドを1秒間に渡って録音した105,829個のデータセットと,ESC-50という,2,000個の5秒間の環境音声記録を50個のクラスに分類したもので実験を行っています.
ここで,○○-SというモデルはImageNetにおける事前学習,○○-PというモデルはAudioSet+ImageNetにおける事前学習モデルです.結果を見ると,どちらのデータセットにおいても,AudioSetのSOTAであったPSLAを超える精度が出ています.人の声や環境音に偏ったデータセットにおいても安定して高い性能を出せるようです.(個人的にはSpeech Commands V2においてAudioSetの事前学習が意味をなしていないことが気になりましたが,論文中では特に言及されていませんでした.)
実験
ASTを手元で動かして,精度や動かしてみた印象を述べられたら良いなと思い,簡単な実験を行ってみました.今回はkaggleのBirdCLEF 2021 – Birdcall Identificationというコンペのデータセットを学習させてみました.データとタスクの説明は以下のとおりです.
- データセット…各音データには,397種類の鳥の鳴き声が含まれており,音データごとにラベルがついています.音データの長さはまちまちであり,音データのどこで鳥が鳴いているかに関してはわかりません.(弱ラベルのみ付与されている)
- タスク…本来のコンペでは,test用の長いデータに対し,5秒区切りでどの鳥が鳴いているか判定します.(複数,または鳴いていない場合もあり)今回は簡単のため,学習時の交差エントロピー誤差の推移を観察してみます.
ベースラインはEfficientNet B0とします.(自分がよく使っているモデルなので),ASTの公式実装ではモデルのサイズでtiny, small, baseと3種類のモデルが用意されているのですが,今回はGPUの都合上一番パラメータ数の少ないASTのtinyモデルを回してみます.どちらも,ImageNetのpretrainedモデルを用い,50epoch回します.その他条件は以下のとおりです.
- 環境
- GPU…RTX 2080 T(11GB)
- CPU…Intel(R) Core(TM) i9-9900KF
- OS…Ubuntu 18.04
- pytorch…1.10.0
- 学習関連
- optimizer…Adam
- 学習率…EfficientNet B0: 5e-4.AST…1e-4.変更した理由は下に記載.
- scheduler…CosineAnnealingLR
結果
epochごとのlossの遷移は以下のようになりました.コードはgithubに置きました.
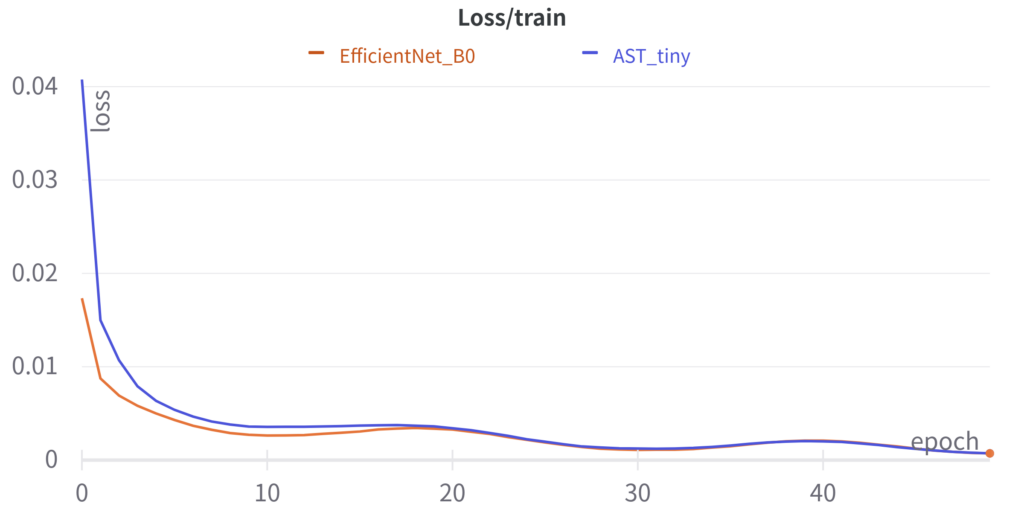
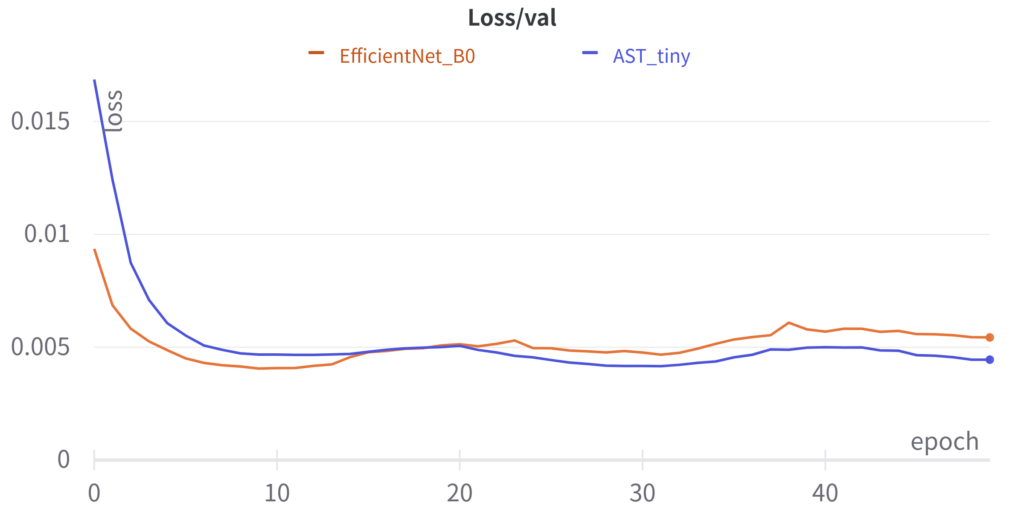
ASTのtinyで,EfficientNet B0と比較しても遜色ない精度が出ていそうなことがわかります.気づいたこととして,どうやらlossが早く落ちる学習率に違いがあるようで,ASTの学習率をEfficientNetの1/5にしたところ,同じような速度でlossが落ち始めました.また,論文ではASTは収束が早いとの記載がありましたが,手元の実験ではそのような結果は出ませんでした.
| EfficientNet B0 | AST tiny | |
|---|---|---|
| 時間 | 6h | 9h |
| パラメータ数 | 4.5 M | 6.0 M |
| 最小train loss | 7.22e-4 | 7.23e-4 |
| 最小valid loss | 4.07e-4 | 4.16e-4 |
使ってみた正直な感想としては,この時間と精度であれば,自分はまだEfficientNetの方を使うかなというところです.しかし,アーキテクチャを最適化したEfficientNetと,ほぼTransformerの構造そのままのASTを比較しているわけですから,効率という面で負けるのも当然という気もします.
まとめ
音データにおけるクラス分類タスクで登場し,AudioSet等で高い精度を出したAudio Spectrogram Transformerを紹介しました.ImageNetの事前学習モデルを使えるということで,私が実施した簡単な実験でも,高い精度が出ることを確認できました.その一方で,学習効率という面ではまだまだ改善の余地があると感じます.最近では,PaSSTというより効率的なアーキテクチャでASTの精度を超えたモデルも提案されているので,今後もTransformer系のモデルに期待していようと思います.
参考文献
- Yuan Gong, Yu-An Chung, and James Glass, “AST: Audio Spectrogram Transformer,” in Interspeech 2021, 2021, pp. 571–575.
- H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jegou, “Training data-efficient image transformers & distillation through attention,” arXiv preprint arXiv:2012.12877, 2020.
- Khaled Koutini, Jan Schlüter, Hamid Eghbal-zadeh, Gerhard Widmer, “Efficient Training of Audio Transformers with Patchout,” arXiv preprint arXiv:2110.05069, 2021.
最近の投稿
- Hmcomm、守山市とAI漏水検知の社会実装フェーズへ移行― 実証成果を踏まえ、2026年度も実証を継続 ― 2026年04月03日
- Hmcomm、AIによる水道管漏水検知の実証が完了― 守山市で成果報告会を開催、熟練調査員と同程度の判定結果を確認 ― 2026年03月18日
- 守山市での漏水検知実証実験に関する取り組みが水道産業新聞に掲載 2026年03月11日
- Hmcomm、山形県企業局と連携し、設備の故障予兆検知の実現に関する取り組みを開始 2026年02月16日
- Hmcomm、内閣官房主催『イチBizアワード』にてESRIジャパン協賛企業賞を受賞― 音×衛星データ×AIによる漏水検知の実装力と社会的価値を評価 ― 2026年02月13日
- 国土交通省「インフラ施設管理AI協議会」 有識者委員として参画― インフラ維持管理DXに関する当社の知見が評価され選定 ― 2025年12月12日
- 守山市における「水道管漏水検知システム」実証が最終フェーズへ― 守山市公式noteにて取り組み進展が紹介されました ― 2025年12月08日
- Hmcomm、SecondSightと連携し、異常音検知AIアプリ「FAST-D」によるLNG気化プラントの設備監視を開始〜夜間巡回業務の一部代替から開始し、保全業務の効率化を推進〜 2025年10月29日
- 守山市での漏水検知実証実験に関する取り組みが水道産業新聞に掲載されました 2025年08月08日
- 「衛星データ×FAST-D 漏水検知システム」が守山市官民連携プロジェクトに採択—Hmcomm、広域から精密まで一気通貫で漏水を検知する実証実験を開始— 2025年07月17日
カテゴリー
アーカイブ
- 2026年4月
- 2026年3月
- 2026年2月
- 2025年12月
- 2025年10月
- 2025年8月
- 2025年7月
- 2025年6月
- 2022年8月
- 2022年7月
- 2022年6月
- 2022年5月
- 2022年4月
- 2022年3月
- 2022年2月
- 2022年1月
- 2021年12月
- 2021年11月
- 2021年10月
- 2021年9月
- 2021年8月
- 2021年7月
- 2021年6月
- 2021年5月
- 2021年4月
- 2021年3月
- 2021年2月
- 2021年1月
- 2020年10月
- 2020年9月
- 2020年8月
- 2020年6月
- 2020年5月
- 2020年2月
- 2019年10月
- 2019年9月
- 2019年4月
- 2018年12月
- 2018年9月
- 2018年6月